Published
- 3 min read
Transformers: The Revolutionary Architecture Powering Modern AI
Introduction
In 2017, a groundbreaking paper titled “Attention Is All You Need” by Vaswani et al. introduced the Transformer architecture, revolutionizing the field of deep learning. This novel approach discarded traditional recurrent and convolutional neural networks in favor of a purely attention-based mechanism, leading to unprecedented performance in sequence modeling tasks.
The Evolution of Sequence Modeling
Before Transformers, sequence modeling was dominated by:
- Recurrent Neural Networks (RNNs)
- Long Short-Term Memory (LSTM) networks
- Gated Recurrent Units (GRUs)
These architectures, while effective, suffered from:
- Sequential processing limitations
- Vanishing gradient problems
- Difficulty in capturing long-range dependencies
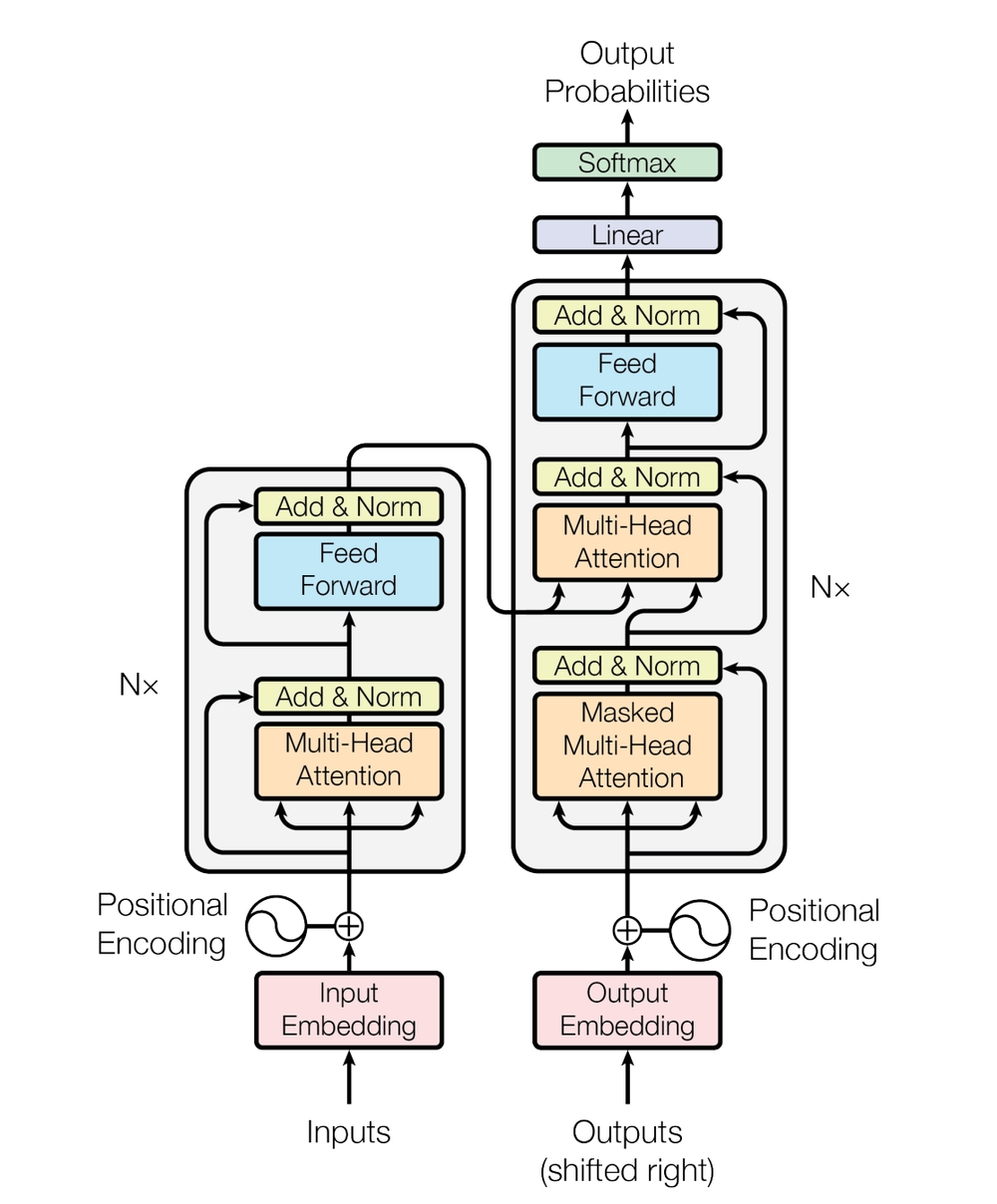
Core Components of the Transformer
1. Encoder-Decoder Architecture
The Transformer employs a sophisticated Encoder-Decoder framework:
Encoder Stack:
- Processes input sequences
- Creates rich contextual representations
- Comprises multiple identical layers
- Each layer contains:
- Multi-head self-attention
- Position-wise feed-forward networks
- Residual connections
- Layer normalization
Decoder Stack:
- Generates output sequences
- Maintains causal attention
- Similar structure to encoder but with:
- Masked multi-head attention
- Encoder-decoder attention
- Position-wise feed-forward networks
2. Self-Attention Mechanism
Scaled Dot-Product Attention
The attention mechanism is the heart of the Transformer:
[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V ]
Where:
- (Q): Query matrix
- (K): Key matrix
- (V): Value matrix
- (d_k): Dimension of keys
Multi-Head Attention
Multi-head attention enables the model to:
- Process different representation subspaces
- Capture various types of relationships
- Compute attention in parallel
- Enhance model capacity
3. Positional Encoding
Since Transformers lack recurrence, positional information is injected through sinusoidal encodings:
[ PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) ] [ PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) ]
Advanced Transformer Variants
1. BERT (Bidirectional Encoder Representations from Transformers)
- Pre-trained on large text corpora
- Uses masked language modeling
- Achieves state-of-the-art results in NLP tasks
2. GPT (Generative Pre-trained Transformer)
- Autoregressive language model
- Trained on massive text datasets
- Powers applications like ChatGPT
3. Vision Transformers (ViT)
- Applies Transformer architecture to computer vision
- Divides images into patches
- Achieves competitive results with CNNs
Applications and Impact
Natural Language Processing
- Machine translation
- Text summarization
- Question answering
- Sentiment analysis
- Named entity recognition
Computer Vision
- Image classification
- Object detection
- Image generation
- Video understanding
Multimodal Applications
- Image captioning
- Visual question answering
- Cross-modal retrieval
- Video-text understanding
Advantages Over Traditional Architectures
-
Parallelization
- Simultaneous processing of sequence elements
- Faster training and inference
- Better hardware utilization
-
Global Context
- Direct modeling of long-range dependencies
- No information decay over distance
- Better understanding of context
-
Scalability
- Handles varying sequence lengths
- Adaptable to different domains
- Efficient transfer learning
Challenges and Future Directions
-
Computational Requirements
- High memory usage
- Large training datasets needed
- Energy consumption concerns
-
Interpretability
- Complex attention patterns
- Black-box nature
- Need for explainability
-
Future Developments
- Sparse attention mechanisms
- Efficient training methods
- Domain-specific optimizations
Practical Implementation Tips
-
Model Selection
- Choose appropriate variant for your task
- Consider computational constraints
- Balance model size and performance
-
Training Considerations
- Use appropriate learning rate schedules
- Implement gradient clipping
- Monitor attention patterns
-
Fine-tuning Strategies
- Layer-wise learning rate decay
- Progressive unfreezing
- Task-specific adaptations
Conclusion
The Transformer architecture has fundamentally transformed the landscape of deep learning, enabling breakthroughs across multiple domains. Its innovative use of attention mechanisms, combined with efficient parallel processing, has set new standards for sequence modeling and beyond.
As we continue to explore and refine this architecture, we can expect even more remarkable applications and improvements in the years to come. The future of AI is being shaped by Transformers, and understanding their principles is crucial for anyone working in machine learning and artificial intelligence.
Ready to dive deeper? Check out our upcoming posts on:
- Advanced Transformer architectures
- Practical implementation guides
- State-of-the-art applications
- Optimization techniques